How Tos¶
The samples and documentation provide sample “Hello World” code that speeds development with the Extract API. The code examples illustrate how to perform Extract PDF operations such as:
Extract as JSON the content & structure of text, table, and figure elements
Extract as JSON the content, structure & renditions of table and figure elements
Extract as JSON the content, structure & renditions of table and figure elements along with tables as CSVs
Extract as JSON the content, structure & renditions of table and figure elements along with Character Bounding Boxes
Structured Information Output Format¶
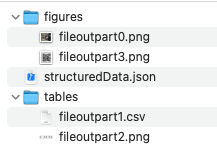
The output of an SDK extract operation is a zip package containing the following:
The structuredData.json file with the extracted content & PDF element structure. See the JSON schema.
A renditions folder(s) containing renditions for each element type selected as input. The folder name is either “tables” or “figures” depending on your specified element type. Each folder contains renditions with filenames that correspond to the element information in the JSON file.
Runtime in-memory authentication¶
The SDK supports providing authentication credentials at runtime. Doing so allows fetching the credentials from a secret server during runtime instead of storing them in a file. Please refer the following samples for details:
Timeout configuration¶
The APIs use inferred timeout properties and provide defaults. However, the SDK supports custom timeouts for the API calls. You can tailor the timeout settings for your environment and network speed. In addition to the details below, you can refer to working code samples:
Java timeout configuration¶
Available properties:
connectTimeout: Default: 4000. The maximum allowed time in milliseconds for creating an initial HTTPS connection.
socketTimeout: Default: 10000. The maximum allowed time in milliseconds between two successive HTTP response packets.
Override the timeout properties via a custom ClientConfig class:
ClientConfig clientConfig = ClientConfig.builder()
.withConnectTimeout(3000)
.withSocketTimeout(20000)
.build();
Node.js timeout configuration¶
Available properties:
connectTimeout: Default: 10000. The maximum allowed time in milliseconds for creating an initial HTTPS connection.
readTimeout: Default: 20000. The maximum allowed time in milliseconds between two successive HTTP response packets.
Override the timeout properties via a custom ClientConfig class:
const clientConfig = PDFToolsSdk.ClientConfig
.clientConfigBuilder()
.withConnectTimeout(15000)
.withReadTimeout(25000)
.build();
Python timeout configuration¶
Available properties:
connectTimeout: Default: 4000. The number of milliseconds Requests will wait for the client to establish a connection to Server.
readTimeout: Default: 10000. The number of milliseconds the client will wait for the server to send a response.
Override the timeout properties via a custom ClientConfig class:
client_config = ClientConfig.builder()
.with_connect_timeout(10000)
.with_read_timeout(40000)
.build()
Extract Text from a PDF¶
Use the sample below to extract text element information from a PDF document.
mvn -f pom.xml exec:java -Dexec.mainClass=com.adobe.platform.operation.samples.extractpdf.ExtractTextInfoFromPDF
public class ExtractTextInfoFromPDF {
// Initialize the logger.
private static final Logger LOGGER = LoggerFactory.getLogger(ExtractTextInfoFromPDF.class);
public static void main(String[] args) {
try {
// Initial setup, create credentials instance.
Credentials credentials = Credentials.serviceAccountCredentialsBuilder()
.fromFile("pdftools-api-credentials.json")
.build();
// Create an ExecutionContext using credentials and create a new operation instance.
ExecutionContext executionContext = ExecutionContext.create(credentials);
ExtractPDFOperation extractPdfOperation = ExtractPDFOperation.createNew();
// Set operation input from a source file.
FileRef source = FileRef.createFromLocalFile("src/main/resources/extractPDFInput.pdf");
extractPdfOperation.setInputFile(source);
extractPdfOperation.addElementToExtract(PDFElementType.TEXT);
// Execute the operation.
FileRef result = extractPdfOperation.execute(executionContext);
// Save the result to the specified location.
result.saveAs("output/ExtractTextInfoFromPDF.zip");
} catch (ServiceApiException | IOException | SdkException | ServiceUsageException ex) {
LOGGER.error("Exception encountered while executing operation", ex);
}
}
}
node src/extractpdf/extract-text-info-from-pdf.js
const ExtractPdfSdk = require('@adobe/pdftools-extract-node-sdk');
try {
// Initial setup, create credentials instance.
const credentials = ExtractPdfSdk.Credentials
.serviceAccountCredentialsBuilder()
.fromFile(`pdftools-api-credentials.json`)
.build();
//Create a clientContext using credentials and create a new operation instance.
const clientContext = ExtractPdfSdk.ExecutionContext.create(credentials),
extractPDFOperation = ExtractPdfSdk.ExtractPDF.Operation.createNew(),
// Set operation input from a source file.
input = ExtractPdfSdk.FileRef.createFromLocalFile(
'resources/extractPdfInput.pdf',
ExtractPdfSdk.ExtractPDF.SupportedSourceFormat.pdf
);
extractPDFOperation.setInput(input);
extractPDFOperation.addElementToExtract(ExtractPdfSdk.PDFElementType.TEXT);
// Execute the operation
extractPDFOperation.execute(clientContext)
.then(result => result.saveAsFile('output/extractTextTableInfoFromPdf.zip'))
.catch(err => console.log(err));
} catch (err) {
console.log("Exception encountered while executing operation", err);
}
python ./extractpdf/extract_txt_from_pdf.py
logging.basicConfig(level=os.environ.get("LOGLEVEL", "INFO"))
try:
# get base path.
base_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# Initial setup, create credentials instance.
credentials = Credentials.service_account_credentials_builder()\
.from_file(base_path + "/pdftools-api-credentials.json") \
.build()
#Create an ExecutionContext using credentials and create a new operation instance.
execution_context = ExecutionContext.create(credentials)
extract_pdf_operation = ExtractPDFOperation.create_new()
#Set operation input from a source file.
source = FileRef.create_from_local_file(base_path + "/resources/extractPdfInput.pdf")
extract_pdf_operation.set_input(source)
# Build ExtractPDF options and set them into the operation
extract_pdf_options: ExtractPDFOptions = ExtractPDFOptions.builder() \
.with_element_to_extract(PDFElementType.TEXT) \
.build()
extract_pdf_operation.set_options(extract_pdf_options)
#Execute the operation.
result: FileRef = extract_pdf_operation.execute(execution_context)
# Save the result to the specified location.
result.save_as(base_path + "/output/ExtractTextInfoFromPDF.zip")
except (ServiceApiException, ServiceUsageException, SdkException):
logging.exception("Exception encountered while executing operation")
Extract Text and Tables¶
The sample below extracts text, tables, and figures element information from a PDF document.
mvn -f pom.xml exec:java -Dexec.mainClass=com.adobe.platform.operation.samples.extractpdf.ExtractTextTableInfoFromPDF
public class ExtractTextTableInfoFromPDF {
// Initialize the logger.
private static final Logger LOGGER = LoggerFactory.getLogger(ExtractTextTableInfoFromPDF.class);
public static void main(String[] args) {
try {
// Initial setup, create credentials instance.
Credentials credentials = Credentials.serviceAccountCredentialsBuilder()
.fromFile("pdftools-api-credentials.json")
.build();
// Create an ExecutionContext using credentials and create a new operation instance.
ExecutionContext executionContext = ExecutionContext.create(credentials);
ExtractPDFOperation extractPdfOperation = ExtractPDFOperation.createNew();
// Set operation input from a source file.
FileRef source = FileRef.createFromLocalFile("src/main/resources/extractPDFInput.pdf");
extractPdfOperation.setInputFile(source);
extractPdfOperation.addElementToExtract(PDFElementType.TEXT).addElementToExtract(PDFElementType.TABLES);
// Execute the operation.
FileRef result = extractPdfOperation.execute(executionContext);
// Save the result to the specified location.
result.saveAs("output/ExtractTextTableInfoFromPDF.zip");
} catch (ServiceApiException | IOException | SdkException | ServiceUsageException ex) {
LOGGER.error("Exception encountered while executing operation", ex);
}
}
}
node src/extractpdf/extract-text-table-info-from-pdf.js
const ExtractPdfSdk = require('@adobe/pdftools-extract-node-sdk');
try {
// Initial setup, create credentials instance.
const credentials = ExtractPdfSdk.Credentials
.serviceAccountCredentialsBuilder()
.fromFile(`pdftools-api-credentials.json`)
.build();
//Create a clientContext using credentials and create a new operation instance.
const clientContext = ExtractPdfSdk.ExecutionContext.create(credentials),
extractPDFOperation = ExtractPdfSdk.ExtractPDF.Operation.createNew(),
// Set operation input from a source file.
input = ExtractPdfSdk.FileRef.createFromLocalFile(
'resources/extractPdfInput.pdf',
ExtractPdfSdk.ExtractPDF.SupportedSourceFormat.pdf
);
extractPDFOperation.setInput(input);
extractPDFOperation.addElementToExtract(ExtractPdfSdk.PDFElementType.TEXT);
extractPDFOperation.addElementToExtract(ExtractPdfSdk.PDFElementType.TABLES);
// Execute the operation
extractPDFOperation.execute(clientContext)
.then(result => result.saveAsFile('output/extractTextTableInfoFromPdf.zip'))
.catch(err => console.log(err));
} catch (err) {
console.log("Exception encountered while executing operation", err);
}
python ./extractpdf/extract_txt_table_info_from_pdf.py
logging.basicConfig(level=os.environ.get("LOGLEVEL", "INFO"))
try:
# get base path.
base_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# Initial setup, create credentials instance.
credentials = Credentials.service_account_credentials_builder()\
.from_file(base_path + "/pdftools-api-credentials.json") \
.build()
#Create an ExecutionContext using credentials and create a new operation instance.
execution_context = ExecutionContext.create(credentials)
extract_pdf_operation = ExtractPDFOperation.create_new()
#Set operation input from a source file.
source = FileRef.create_from_local_file(base_path + "/resources/extractPdfInput.pdf")
extract_pdf_operation.set_input(source)
# Build ExtractPDF options and set them into the operation
extract_pdf_options: ExtractPDFOptions = ExtractPDFOptions.builder() \
.with_element_to_extract(PDFElementType.TEXT) \
.with_element_to_extract(PDFElementType.TABLES) \
.build()
extract_pdf_operation.set_options(extract_pdf_options)
#Execute the operation.
result: FileRef = extract_pdf_operation.execute(execution_context)
# Save the result to the specified location.
result.save_as(base_path + "/output/ExtractTextTableInfoFromPDF.zip")
except (ServiceApiException, ServiceUsageException, SdkException):
logging.exception("Exception encountered while executing operation")
Extract Text and Tables (w/ Renditions)¶
The sample below extracts text, table, and figure element information as well as table renditions from PDF Document. Note that the output is a zip containing the structured information along with renditions.
mvn -f pom.xml exec:java -Dexec.mainClass=com.adobe.platform.operation.samples.extractpdf.ExtractTextTableInfoWithRenditionsFromPDF
public class ExtractTextTableInfoWithRenditionsFromPDF {
// Initialize the logger.
private static final Logger LOGGER = LoggerFactory.getLogger(ExtractTextTableInfoWithRenditionsFromPDF.class);
public static void main(String[] args) {
try {
// Initial setup, create credentials instance.
Credentials credentials = Credentials.serviceAccountCredentialsBuilder()
.fromFile("pdftools-api-credentials.json")
.build();
// Create an ExecutionContext using credentials and create a new operation instance.
ExecutionContext executionContext = ExecutionContext.create(credentials);
ExtractPDFOperation extractPdfOperation = ExtractPDFOperation.createNew();
// Set operation input from a source file.
FileRef source = FileRef.createFromLocalFile("src/main/resources/extractPDFInput.pdf");
extractPdfOperation.setInputFile(source);
extractPdfOperation.addElementsToExtract(Arrays.asList(PDFElementType.TEXT, PDFElementType.TABLES));
extractPdfOperation.addElementToExtractRenditions(PDFElementType.TABLES);
// Execute the operation.
FileRef result = extractPdfOperation.execute(executionContext);
// Save the result to the specified location.
result.saveAs("output/ExtractTextTableInfoWithRenditionsFromPDF.zip");
} catch (ServiceApiException | IOException | SdkException | ServiceUsageException ex) {
LOGGER.error("Exception encountered while executing operation", ex);
}
}
}
node src/extractpdf/extract-text-table-info-with-tables-renditions-from-pdf.js
const ExtractPdfSdk = require('@adobe/pdftools-extract-node-sdk');
try {
// Initial setup, create credentials instance.
const credentials = ExtractPdfSdk.Credentials
.serviceAccountCredentialsBuilder()
.fromFile(`pdftools-api-credentials.json`)
.build();
//Create a clientContext using credentials and create a new operation instance.
const clientContext = ExtractPdfSdk.ExecutionContext.create(credentials)
extractPDFOperation = ExtractPdfSdk.ExtractPDF.Operation.createNew(),
// Set operation input from a source file.
input = ExtractPdfSdk.FileRef.createFromLocalFile(
'resources/extractPdfInput.pdf',
ExtractPdfSdk.ExtractPDF.SupportedSourceFormat.pdf
);
extractPDFOperation.setInput(input);
extractPDFOperation.addElementToExtract(ExtractPdfSdk.PDFElementType.TEXT);
extractPDFOperation.addElementToExtract(ExtractPdfSdk.PDFElementType.TABLES);
extractPDFOperation.addElementToExtractRenditions(ExtractPdfSdk.PDFElementType.TABLES);
// Execute the operation
extractPDFOperation.execute(clientContext)
.then(result => result.saveAsFile('output/extractTextTableInfoWithTablesRenditionsFromPdf.zip'))
.catch(err => console.log(err));
} catch (err) {
console.log("Exception encountered while executing operation", err);
}
python ./extractpdf/extract_txt_table_info_with_rendition_from_pdf.py
logging.basicConfig(level=os.environ.get("LOGLEVEL", "INFO"))
try:
# get base path.
base_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# Initial setup, create credentials instance.
credentials = Credentials.service_account_credentials_builder() \
.from_file(base_path + "/pdftools-api-credentials.json") \
.build()
# Create an ExecutionContext using credentials and create a new operation instance.
execution_context = ExecutionContext.create(credentials)
extract_pdf_operation = ExtractPDFOperation.create_new()
# Set operation input from a source file.
source = FileRef.create_from_local_file(base_path + "/resources/extractPdfInput.pdf")
extract_pdf_operation.set_input(source)
# Build ExtractPDF options and set them into the operation
extract_pdf_options: ExtractPDFOptions = ExtractPDFOptions.builder() \
.with_elements_to_extract([PDFElementType.TEXT, PDFElementType.TABLES]) \
.with_element_to_extract_renditions(PDFElementType.TABLES) \
.build()
extract_pdf_operation.set_options(extract_pdf_options)
# Execute the operation.
result: FileRef = extract_pdf_operation.execute(execution_context)
# Save the result to the specified location.
result.save_as(base_path + "/output/ExtractTextTableWithTableRendition.zip")
except (ServiceApiException, ServiceUsageException, SdkException):
logging.exception("Exception encountered while executing operation")
Extract Text and Tables and Character Bounding Boxes (w/ Renditions)¶
The sample below extracts table renditions and bounding boxes for characters present in text blocks(paragraphs, list, headings), in addition to text, table, and figure element information from PDF Document. Note that the output is a zip containing the structured information along with renditions.
mvn -f pom.xml exec:java -Dexec.mainClass=com.adobe.platform.operation.samples.extractpdf.ExtractTextTableInfoWithCharBoundsFromPDF
public class ExtractTextTableInfoWithCharBoundsFromPDF {
// Initialize the logger.
private static final Logger LOGGER = LoggerFactory.getLogger(ExtractTextTableInfoWithCharBoundsFromPDF.class);
public static void main(String[] args) {
try {
// Initial setup, create credentials instance.
Credentials credentials = Credentials.serviceAccountCredentialsBuilder()
.fromFile("pdftools-api-credentials.json")
.build();
// Create an ExecutionContext using credentials and create a new operation instance.
ExecutionContext executionContext = ExecutionContext.create(credentials);
ExtractPDFOperation extractPdfOperation = ExtractPDFOperation.createNew();
// Set operation input from a source file.
FileRef source = FileRef.createFromLocalFile("src/main/resources/extractPDFInput.pdf");
extractPdfOperation.setInputFile(source);
extractPdfOperation.addElementsToExtract(Arrays.asList(PDFElementType.TEXT, PDFElementType.TABLES));
extractPdfOperation.addElementToExtractRenditions(PDFElementType.TABLES);
extractPdfOperation.addCharInfo(Boolean.TRUE);
// Execute the operation.
FileRef result = extractPdfOperation.execute(executionContext);
// Save the result to the specified location.
result.saveAs("output/ExtractTextTableInfoWithCharBoundsFromPDF.zip");
} catch (ServiceApiException | IOException | SdkException | ServiceUsageException ex) {
LOGGER.error("Exception encountered while executing operation", ex);
}
}
}
node src/extractpdf/extract-text-table-info-with-char-bounds-from-pdf.js
const ExtractPdfSdk = require('@adobe/pdftools-extract-node-sdk');
try {
// Initial setup, create credentials instance.
const credentials = ExtractPdfSdk.Credentials
.serviceAccountCredentialsBuilder()
.fromFile(`pdftools-api-credentials.json`)
.build();
//Create a clientContext using credentials and create a new operation instance.
const clientContext = ExtractPdfSdk.ExecutionContext.create(credentials)
extractPDFOperation = ExtractPdfSdk.ExtractPDF.Operation.createNew(),
// Set operation input from a source file.
input = ExtractPdfSdk.FileRef.createFromLocalFile(
'resources/extractPdfInput.pdf',
ExtractPdfSdk.ExtractPDF.SupportedSourceFormat.pdf
);
extractPDFOperation.setInput(input);
extractPDFOperation.addElementToExtract(ExtractPdfSdk.PDFElementType.TEXT);
extractPDFOperation.addElementToExtract(ExtractPdfSdk.PDFElementType.TABLES);
extractPDFOperation.addElementToExtractRenditions(ExtractPdfSdk.PDFElementType.TABLES);
extractPDFOperation.addCharInfo(Boolean.TRUE);
// Execute the operation
extractPDFOperation.execute(clientContext)
.then(result => result.saveAsFile('output/extractTextTableInfoWithCharBoundsFromPDF.zip'))
.catch(err => console.log(err));
} catch (err) {
console.log("Exception encountered while executing operation", err);
}
python ./extractpdf/extract_txt_table_info_with_char_bounds_from_pdf.py
logging.basicConfig(level=os.environ.get("LOGLEVEL", "INFO"))
try:
# get base path.
base_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# Initial setup, create credentials instance.
credentials = Credentials.service_account_credentials_builder()\
.from_file(base_path + "/pdftools-api-credentials.json") \
.build()
#Create an ExecutionContext using credentials and create a new operation instance.
execution_context = ExecutionContext.create(credentials)
extract_pdf_operation = ExtractPDFOperation.create_new()
#Set operation input from a source file.
source = FileRef.create_from_local_file(base_path + "/resources/extractPdfInput.pdf")
extract_pdf_operation.set_input(source)
# Build ExtractPDF options and set them into the operation
extract_pdf_options: ExtractPDFOptions = ExtractPDFOptions.builder() \
.with_elements_to_extract([PDFElementType.TEXT, PDFElementType.TABLES]) \
.with_element_to_extract_renditions(PDFElementType.TABLES) \
.with_get_char_info(True) \
.build()
extract_pdf_operation.set_options(extract_pdf_options)
#Execute the operation.
result: FileRef = extract_pdf_operation.execute(execution_context)
# Save the result to the specified location.
result.save_as(base_path + "/output/ExtractTextTableInfoWithCharBoundsFromPDF.zip")
except (ServiceApiException, ServiceUsageException, SdkException):
logging.exception("Exception encountered while executing operation")
Extract Text and Tables and Table Structure as CSV (w/ Renditions)¶
The sample below adds option to get CSV output for tables in addition to extracting text, table, and figure element information as well as table renditions from PDF Document. Note that the output is a zip containing the structured information along with renditions.
mvn -f pom.xml exec:java -Dexec.mainClass=com.adobe.platform.operation.samples.extractpdf.ExtractTextTableInfoWithTableStructureFromPdf
public class ExtractTextTableInfoWithTableStructureFromPdf {
// Initialize the logger.
private static final Logger LOGGER = LoggerFactory.getLogger(ExtractTextTableInfoWithTableStructureFromPdf.class);
public static void main(String[] args) {
try {
// Initial setup, create credentials instance.
Credentials credentials = Credentials.serviceAccountCredentialsBuilder()
.fromFile("pdftools-api-credentials.json")
.build();
// Create an ExecutionContext using credentials and create a new operation instance.
ExecutionContext executionContext = ExecutionContext.create(credentials);
ExtractPDFOperation extractPdfOperation = ExtractPDFOperation.createNew();
// Set operation input from a source file.
FileRef source = FileRef.createFromLocalFile("src/main/resources/extractPDFInput.pdf");
extractPdfOperation.setInputFile(source);
extractPdfOperation.addElementsToExtract(Arrays.asList(PDFElementType.TEXT, PDFElementType.TABLES));
extractPdfOperation.addElementToExtractRenditions(PDFElementType.TABLES);
extractPdfOperation.addTableStructureFormat(TableStructureType.CSV);
// Execute the operation.
FileRef result = extractPdfOperation.execute(executionContext);
// Save the result to the specified location.
result.saveAs("output/ExtractTextTableInfoWithTableStructureFromPdf.zip");
} catch (ServiceApiException | IOException | SdkException | ServiceUsageException ex) {
LOGGER.error("Exception encountered while executing operation", ex);
}
}
}
node src/extractpdf/extract-text-table-info-with-tables-renditions-from-pdf.js
const ExtractPdfSdk = require('@adobe/pdftools-extract-node-sdk');
try {
// Initial setup, create credentials instance.
const credentials = ExtractPdfSdk.Credentials
.serviceAccountCredentialsBuilder()
.fromFile(`pdftools-api-credentials.json`)
.build();
//Create a clientContext using credentials and create a new operation instance.
const clientContext = ExtractPdfSdk.ExecutionContext.create(credentials)
extractPDFOperation = ExtractPdfSdk.ExtractPDF.Operation.createNew(),
// Set operation input from a source file.
input = ExtractPdfSdk.FileRef.createFromLocalFile(
'resources/extractPdfInput.pdf',
ExtractPdfSdk.ExtractPDF.SupportedSourceFormat.pdf
);
extractPDFOperation.setInput(input);
extractPDFOperation.addElementToExtract(ExtractPdfSdk.PDFElementType.TEXT);
extractPDFOperation.addElementToExtract(ExtractPdfSdk.PDFElementType.TABLES);
extractPDFOperation.addElementToExtractRenditions(ExtractPdfSdk.PDFElementType.TABLES);
extractPdfOperation.addTableStructureFormat(ExtractPdfSdk.TableStructureType.CSV);
// Execute the operation
extractPDFOperation.execute(clientContext)
.then(result => result.saveAsFile('output/extractTextTableInfoWithTableStructureFromPdf.zip'))
.catch(err => console.log(err));
} catch (err) {
console.log("Exception encountered while executing operation", err);
}
python ./extractpdf/extract_txt_table_info_with_table_structure_from_pdf.py
logging.basicConfig(level=os.environ.get("LOGLEVEL", "INFO"))
try:
# get base path.
base_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# Initial setup, create credentials instance.
credentials = Credentials.service_account_credentials_builder() \
.from_file(base_path + "/pdftools-api-credentials.json") \
.build()
# Create an ExecutionContext using credentials and create a new operation instance.
execution_context = ExecutionContext.create(credentials)
extract_pdf_operation = ExtractPDFOperation.create_new()
# Set operation input from a source file.
source = FileRef.create_from_local_file(base_path + "/resources/extractPdfInput.pdf")
extract_pdf_operation.set_input(source)
# Build ExtractPDF options and set them into the operation
extract_pdf_options: ExtractPDFOptions = ExtractPDFOptions.builder() \
.with_elements_to_extract([PDFElementType.TEXT, PDFElementType.TABLES]) \
.with_element_to_extract_renditions(PDFElementType.TABLES) \
.with_table_structure_format(TableStructureType.CSV) \
.build()
extract_pdf_operation.set_options(extract_pdf_options)
# Execute the operation.
result: FileRef = extract_pdf_operation.execute(execution_context)
# Save the result to the specified location.
result.save_as(base_path + "/output/ExtractTextTableWithTableStructure.zip")
except (ServiceApiException, ServiceUsageException, SdkException):
logging.exception("Exception encountered while executing operation")